

In the 1980’s “home computers” first became widely available and affordable from popular brands such as Sinclair, Commodore, Acorn and Atari. This isn’t too different to today, if you want a computer you can buy one from Dell, Asus, Lenovo, Apple and so on, but with one huge difference – they can all communicate with each other regardless of the brand you chose.
These days we have widely adopted standards that mean we can communicate freely via the internet or messaging services without having to worry about which phone, tablet or PC we bought, but this common ground didn’t always exist. In the early days of computing one of the main barriers to communication was down to how each machine stored text in memory. To understand why this could cause problems we first need to understand two facts:
1. Computers can only understand and store binary. Therefore, if you want to use a computer, you must find a way to turn all information into binary. This is called Encoding
2. Encoding – this is the process of turning any real world information (images, sounds, text and so on) into numbers. These numbers can then be stored and processed as binary inside a computer.
When the first computers came along, there were no real standards and so companies simply made up methods of encoding data which suited the design of their machine. This made compatibility with other machines difficult at best.
Why is this such a problem? Well, think about it, without a standard (something everyone agrees to use/do) way of communicating we wouldn’t have the internet, WWW, text messaging CD/DVD/blu-ray players or indeed anything that we find useful these days. Standards are the reason that when you send a message from your iPhone to someone who has a Samsung phone, it appears exactly as you expected it to and not a jumbled mess of nonsense.
In this section we look in to how data must be transformed from “real world” or “analogue” data into a digital form in order to be used. Furthermore, you learn about some of the well defined, standard ways of doing this which enable communication and data exchange amongst different devices regardless of manufacturer.
Click to jump to the relevant section:
What is encoding?
A keyboard is connected to a computer via a wire (yes, I know you can get wireless equipment, but lets stick to a simple example). That wire conducts electricity and therefore the information that passes down the wire and in to your computer is in the form of electrical signals.
Knowing, as you do, that a computer is an electronic device, it should not come as a surprise that if you want to get data or information in to a computer (input) then it must first be converted in to an electrical signal that the computer can understand. What kind of electrical signals do computers understand? You already know the answer – binary signals.
In order to communicate with a computer we must turn all information from the real world (sometimes called analogue data) into binary form. This translation from real world to binary is called “encoding.” How difficult this is to achieve will depend on the type of information we are trying to convert – text, images, sound and so on.
Text is one of the simplest forms of data to encode and it all begins with your keyboard. When you press a key, you are pressing a button which closes a circuit underneath. This is a complicated way of saying “you are pressing a switch.” Keyboards have a dedicated chip which scans the rows and columns of your keyboard for any switches that have been pressed and when this happens, it creates a unique binary code for that particular key and sends it down the wire to the device it is attached to.
You could design and create a keyboard of your very own and so long as you generate the correct code for each key when pressed, it would work with any modern computer system. Computers expect data from keyboards to be in a very specific, set, standard form.
Today, there is one universal, world wide adopted standard for assigning binary numbers to an individual number, letter or symbol and that is Unicode. This GCSE, however, requires you to learn about its predecessor ASCII as well.
Text encoding
You now know that encoding is turning things (such as letters and symbols) into numbers so we can store and process it using a computer. Our exam ready definition, then, is as follows:
Text Encoding = A method of turning each character (letter, number or symbol) into a unique numeric binary code
If I asked you to come up with your own method of turning letters into numbers, you’d probably do the following:
a=1, b=2, c=3 and so forth.
There is nothing wrong with this whatsoever and isn’t really far off the truth, but due to some hangovers from old methods of communication, that’s not actually how it works in real hardware. Indeed, ASCII, which we discuss below, dedicates the first 32 numbers as hidden control characters that used to handle communication between devices. This is no longer needed in modern systems, but remains because standards are set in stone and very rarely change without good reason because you’d break all older devices almost instantly if you suddenly re-arranged your encoding.
There are two main standard methods of doing this that we care about:
- ASCII
- Unicode
Each works on a similar premise – each letter, number or symbol is assigned a unique, fixed size binary number. In the case of ASCII these are 8 bit numbers and for Unicode, 16 bits.
We will look at each in more detail below.
ASCII encoding
ASCII stands for the “American Standard Code for Information Interchange.” This is all fairly self explanatory. The word standard simply means “an agreed method” of implementing something – in this case, encoding text into numbers. Standards are everywhere and we take them for granted, but without them most of our modern world would fall apart at the seams. They’re so important that there’s a dedicated international organisation that looks after them all and makes sure everyone is using the same methods or information. They’re called “ISO” or International Office for Standardization.
ASCII was developed and released in 1963 as a standard for teletype machines. These were huge machines that were used for sending messages over long distances way before email had even been dreamed of. The teletype operator would hit a key on their keyboard which would generate an electrical signal that would then be sent one by one down a telephone line to another teletype machine that would automatically print out each letter as it was received. The ASCII standard was necessary because otherwise you’d hit a key on your teletype, say “R” and if the recipient used a different encoding or standard, it may well print out a “Q” or something equally useless. ASCII was a guarantee that everyone was communicating in the same way.

ASCII had an astoundingly long life and remained in popular use well into the early 2000’s. Modern computers can still use and understand the ASCII standard and it has been incorporated into the newer Unicode format, so technically it lives on and is still in use today.
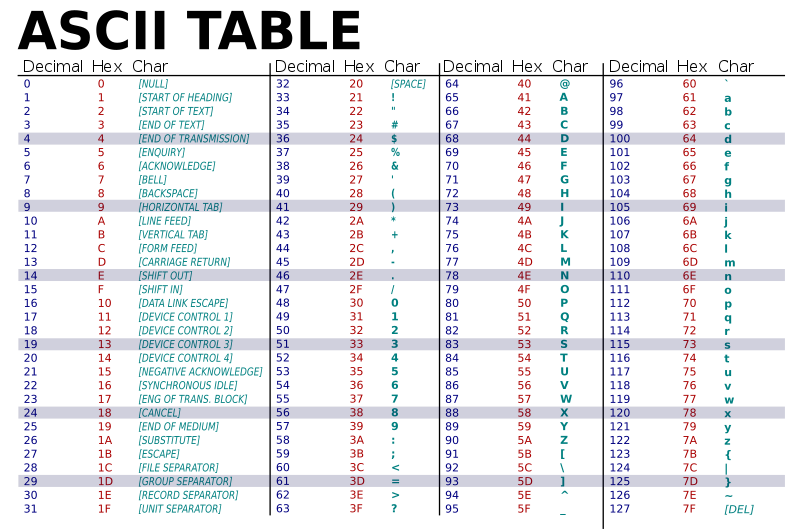
ASCII maps each letter, number or symbol to an 8 bit binary number (originally it was 7). It is important to emphasise for your exam that it doesn’t matter which character it is, you will always use 8 bits for each character. This means the amount of storage required for each character in ASCII is the same and is fixed regardless of which letter, number or symbol it is.
ASCII – a summary:
What is it?
- A method of encoding letters, numbers and symbols into binary
- ASCII uses 7 bits per character but you can also say 8 bits in the exam (because it is sometimes…)
- Stands for “American Standard Code for Information Interchange.” So now you can brighten people’s day with your shining knowledge of acronyms.
Advantages
- A standard method of encoding
- Only uses 7/8 bits per character so it doesn’t require a great deal of storage PER CHARACTER (you must emphasise this in your exam)
Disadvantages
- Cannot encode anything that isn’t English! Therefore it’s not suitable for encoding any other world languages.
- Can only encode a maximum of 127 characters (7 bit ASCII) or a maximum of 256 for 8 bit ASCII
A note on “extended ASCII”:
In 2018, OCR decided to ask one of their more bizarre questions – “What is the difference between ASCII and Extended ASCII” to which most students did one of two things:
- Scratched their heads and looked confused
- Wrote something along the lines of “one is extended.”
Personally, I love this quote, which is referenced no less than 3 times, from everyone’s favourite homework generator Wikipedia:
“The use of the term is sometimes criticized,[1][2][3]because it can be mistakenly interpreted to mean that the ASCII standard has been updated to include more than 128 characters or that the term unambiguously identifies a single encoding, neither of which is the case.”
So there, OCR, stop being naughty.
This was a really bizarre/naughty move on OCR’s part as nowhere in their specification is Extended ASCII mentioned and no teacher in their right mind would think they should mention it either. In case it becomes an OCR favourite, you should know:
- Their examiners are mysterious people
- Extended ASCII incorporates all of the 7 bit ASCII codes and then extends these as 8 bit or longer standard which contains extra characters or symbols which can be used.
Unicode
Unicode takes the concept of ASCII and simply extends it to fix all of the problems with ASCII. Unicode uses more bits per character (it’s only downside) but the trade off is there are now Unicode encodings for every known language in the world, all printable symbols and even emojis. Yes. Emojis are an international binary standard.
Unicode – a summary:
What is it?
- A world wide standard (the “unicode consortium,” no less) for encoding all letters, numbers, symbols of any and all languages
- Unicode has different variations of its standard which vary the number of bits used per character
- UTF-8 uses 8 bits per character, however some may be sent as two bytes, making 16 bits for a single character
- UTF-16 uses 16 bits per character
Advantages
- A world wide standard which has been adopted by virtually all electronics manufacturers and devices on the market today.
- Can represent the characters of all known languages
- UTF-8 actually incorporates (or is compatible with) ASCII
Disadvantages
- Requires more bits per character than ASCII
Quick 10 second text encoding summary
What you should know:
- Text encoding = turning each individual character into a unique binary number
- We use standards to decide what number to assign to each character
- Standards mean that devices can communicate, regardless of hardware or software used
- ASCII is a 7/8 bit standard used to encode English characters and numbers into binary
- ASCII cannot handle other languages
- Unicode is a worldwide adopted standard for encoding all languages
- It is 8 or 16 bit, but usually we say 16 bit for clarity/simplicity
- Unicode is clearly far more useful than ASCII as it has unique codes for all known languages