

In this section (click to jump):
Performance Factors
People that look after networks are odd people. I once convinced a student that every network had a guardian figure called the Server Room Urchin, a being that only existed in networking and server rooms. Their sole existence revolved around massaging data through the cables and overseeing the safe transmission of packets through the network. Unfortunately, putting this down as an answer to an exam question on how networks work won’t get you any marks. Still, it’d make the examiner smile after seeing the same wrong answer 500 times in a row. If you’re going to fail, go out in style.
In all seriousness, networks do not always perform as you may expect. For example, the average desktop PC is fitted with a gigabit (1000 mbps) network interface card, but you will never actually achieve a stable 1000mbps transfer speed when copying data over a network. Why is this?
The answer is not straight forward. There are multiple factors that all have a measurable effect on how quickly data can be transferred across a network. When we think on a global, internet scale, then these factors become even more variable as data will be transferred through multiple networks, all with differing levels of users, equipment, usage and so forth.
The factors which affect network performance are:
- Available bandwidth
- The types of cables used
- The number of users on the network
- The amount and type of traffic being sent through the network
- Distance that data is travelling
- Whether the connection is wired or wireless
- Interference
Bandwidth
Bandwidth is a measure of the capacity of a connection or cable. It is not, necessarily, a measure of speed.
That is a very confusing statement and bandwidth is an often misunderstood concept because instinctively we want to say that more bandwidth = more speed and… well, it does in terms of the time taken to send a chunk of data will reduce but actually the speed that data travelled was the same as before. How can we easily understand this concept? An analogy – consider the roads:

A dual carriage way has a maximum speed limit of 70 mph. It has two lanes. Let’s presume that we stand on a bridge over the road – how many cars can pass under the bridge every second? Lets say 2 cars in each lane, that’s 4 cars per second. The “bandwidth” of this road is 4 cars per second.
Now lets add another lane:

Let’s do the same experiment again – how many cars can now pass under our bridge every second? Well, using the same estimate as before, it doesn’t take a genius to work out we can now fit 6 cars per second. This road, then, has a bandwidth of 6 cars per second.
So, we can now get more cars down our road per second. But wait… the important thing here is we did not increase the speed limit. The speed limit on this road is still 70mph. All we did was increase the capacity of the road. This is why bandwidth is not really a measure of speed – yes you will get more stuff to you quicker, but it’s as a result of increased capacity and not increased speed.
In a computing context, then, bandwidth can be summarised as follows:
Definition: Bandwidth is a measure of the amount of data that can be sent per second through a transmission media (cable/wireless)
- We measure bandwidth in Bits Per Second (Bps) or these days, its Megabits (Mbps) or Gigabits (Gbps) per second.
- The higher the bandwidth, the greater volume of data that can be sent every second down a cable
- It is not a measure of how fast the data travels
Type of Cable (Transmission Media)
The internet has evolved over time and so has the technology we use to transmit electrical signals from one place to another. As internet usage grew, it enveloped a range of transmission media (types of cable) which had been traditionally used to transmit other things such as TV signals and telephone calls. The type of cable used in networking can make a vast difference to the quality, robustness, bandwidth available and overall speed of transmission.
Types of wired media:
The most common types of network transmission media are shown below:




Fibre Optic
What is it? Fibre Optic cable is made up of either glass or plastic strands and data is transmitted as light signals. This is by far the fastest form of transmission media – think about it, nothing in the known universe is faster than light (unless you’re some kind of God reading this and you know better, in which case, give us a nudge, it’d be really useful to know about something faster than light. Unless it would break the universe, in which case you might as well keep it to yourself.)
Fibre is the future of networking to the point that there is currently a massive program of national network upgrades taking place in the UK. All of the old telephone network infrastructure is being replaced. Old copper telephone cables are being replaced with fibre optic cables, which literally involves the digging up of footpaths and roads, removing the old cables and laying new ones.
This roll out is part of what is known as FTTP or Fibre To The Premise. Previously, networks would use fibre connections to a certain point, usually an exchange (one of those big green boxes by the side of the pavement) after which copper cables were used to the end user. This meant that wherever fibre met copper, there was a slowdown or “bottleneck.” With FTTP, fibre cables now run almost to your house, office or other building and only the very last part of the connection from the footpath into your house being copper cable. This explains why suddenly ISP companies have been able to offer you vastly increased internet connection speeds.
Advantages:
- The fastest type of transmission media
- Has the highest bandwidth of any media (make sure you know what bandwidth actually means)
- Multiple signals can be sent down a single strand of optical fibre
- Cables can be very, very long without suffering signal degradation, interference or loss
- Incredibly useful for transferring huge amounts of data over really long distances (under sea cables are all fibre optic)
Disadvantages:
- More expensive to manufacture and install than copper based cables
- Can be fragile / have a limit to how far you can bend the cable
Cat 5 or 6 (or “Ethernet” cable)
What is it? Twisted pairs of copper cables inside an insulated casing. This is the single most common type of cable used in a network. Have a look behind a computer in school if you don’t know what it is… did you look? What a fascinating world it is we live in.
Some clever person discovered that by twisting wires together in pairs you drastically reduce any interference or errors that occur during data transmission. The more twists, the better this effect is (cat 6 is more twisted than cat 5 (and therefore get’s arrested more often)).
MASSIVE EXAM WARNING!!
If you are asked what “ethernet” is, you cannot say “It is a cable.” Ethernet is NOT a cable (which is confusing, considering we just called this Cat 5 cable Ethernet Cable). Ethernet is a PROTOCOL which defines how data is physically sent as electrical signals down a cable. Be careful, you have been warned!
Advantages:
- Relatively cheap, widely available
- Easy to customise or make cables of any desired length
- A “standard” cable type – all computers with a network card and an RJ45 connector will expect a cat5 or 6 cable to be plugged in to it
- High bandwidth
- Fairly robust, you can route it almost anywhere without worrying.
Disadvantages:
- Suffers signal degradation on long lengths of cable. Generally a maximum of 100m at a time is recommended.
Types of Ethernet cable (fastest to slowest)
- Cat 6
- Cat 5e
- Cat 5
Coaxial
What is it? Robust, shielded and insulated copper cable used to transmit TV signals (aerial cable) as well as satellite and broadband data. Versatile and robust.
Advantages:
- Robust, reliable cabling suitable for indoor and outdoor use
- Higher bandwidth than telephone cable
- Well shielded (insulated) from interference
Disadvantages:
- Requires different types of connectors than “standard” Ethernet
- Cable can be of varying quality, this quality will affect bandwidth and data transmission rates
Telephone Cable
What is it? A standard type (RJ11) of cable with four internal wires which are used to transmit voice and digital data. This standard has been around since the 1970’s and is currently being largely phased out in favour of RJ45 (ethernet), coaxial and fibre connections.
Advantages:
- Has been widely used do to its use as the standard cable in telephone networks
- Can provide a reasonable amount of bandwidth
- Extremely cheap and ubiquitous
Disadvantages:
- Lacks bandwidth required by modern networking standards
- Currently being phased out in many places
Number of Users
As more users are connected to a network, there is more traffic being sent and received. This in turn places more burden on the switches and routers being used, servers may take longer to respond at peak times (a whole class logging on together maybe) and more of the available bandwidth will be used up at any one time.
Amount and Type of Traffic
Not all traffic is created equal. Indeed, during the presidency of Donald Trump American ISP’s were elated as Mr Trump decided to sign an executive order allowing them to charge different amounts depending on the kind of data sent or received. If this sounds naughty to you then you’d be right, it is. The internet works on the principle of “net neutrality” which means all data is treated equally regardless of its type. This ensures that the internet is a “fair” place where things are not deliberately slowed down because you haven’t paid enough…
Some types of activity, however, clearly create more traffic than others. When you send an email, a message on your phone or send a snapchat or similar, you are not using up a massive amount of bandwidth. These are things that do not cause large amounts of data to be sent as packets across the network. However, if you start streaming a song or watching a video then this places a different kind of demand on a network. Streaming requires lots of bandwidth, reliably, for a long period of time – otherwise you get the dreaded swirly circles of buffering doom.
As a result, network providers have to ensure they have sufficient bandwidth to provide a stable service when thousands of people all start watching YouTube at the same time and this can cost a significant amount of cash. If there isn’t sufficient bandwidth to cope with demand, packets start to get lost, buffering happens or users notice the network being slower than they would normally expect.
Distance
Physics. It always has to throw a spanner in the works, doesn’t it? The fact is that electric signals suffer from two things:
- Interference
- Resistance
Interference can happen at any point in a data transmission – the most obvious example of this would be during a thunder storm

You don’t need lightening to strike something for it to be a real issue – just the build up of static in the air can be enough to really affect electronic devices. I’ve had many things such as hard drives and motherboards that have given up the will to live after a storm has passed over.
Another example is something called “cross talk” which is where wires that are bundled together actually start to interfere with each other. This doesn’t seem possible but is a genuine problem, which was partially resolved when someone realised you could twist wires round each other and for some odd reason it really reduced interference.
Resistance is easily explained. If I try to shove you down a pipe that’s just wide enough for you to fit in, it’s going to be a bit of a struggle. You’re likely to get stuck against the sides and the friction of your clothing won’t help either. Don’t worry, though, I’m nothing if not persistent so I stick at it and drag you through the pipe by your feet and we all agree the experience was a life changing one.
However, during the ordeal, you got rather hot because of the friction inside the pipe and one or two bits and pieces fell off you on the way through. Not the best outcome – your resistance was too high, so we decide to have another go.

This time I cover you in grease and chuck a bit of Castrol GTX over you for good measure. Now you slip through the pipe without any problems and not a single thing falls off you. Success – we reduced your resistance and now you can travel through a pipe without the risk of losing important bits of you.
Every type of physical transmission media has some kind of resistance and as electricity travels down a cable, energy is lost in the form of heat. In a data cable this results in the signal strength becoming weaker and weaker. There are ways around this – thicker cable for example has much less resistance but costs more, is physically bigger so takes up more room and isn’t ideal. This explains why a run of Cat 5 Ethernet cable has a maximum length of 100m before you need to use a repeater or another networking device to boost the signal before transmitting it again.
Authority – Client-Server and Peer to Peer
Authority in a networking context simply means “who or what is in control of the network?”
Previously, we learned that servers play an important role as central points on a network. They can also be used to maintain complete control over the network, every device connected to the network and everything they are allowed to do. This model of central control is called a Client-Server network and is the dominant type of network in use today.
However, not all networks require or want this central control. Sometimes we need to just set up a network quickly to share some data or we want to connect to something once only. In many cases, having central control would be either unnecessary or undesirable. In these cases peer to peer networks can be created where no one device maintains control over the others, everything is equal.
You need to know about these two methods of network management/control/authority in more detail for your exam.
Client – Server Networks
This section is all about who has control over the network and how the devices are connected together. In a Client – Server network, there is a clearly defined structure to the network and it can be easily controlled from a central point. Its important you can discuss the advantages and disadvantages of these networking structures and also avoid one or two common pit falls.
You will often see diagrams of Client – Server networks that look something like this:
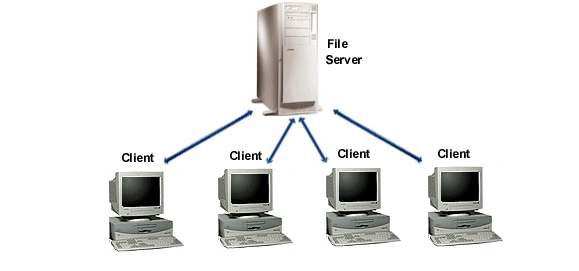
Why? Because all the devices on the network are shown as having a direct connection to the server. This is just nuts – if we did this then we’d need the server to have one network card for every device connected to it! This is absurd. Also I don’t understand why on all diagrams the computers appear to be 100% up to date, blazingly fast 16mhz 386 machines from 1992.
What should it look like? Something a bit more like this:
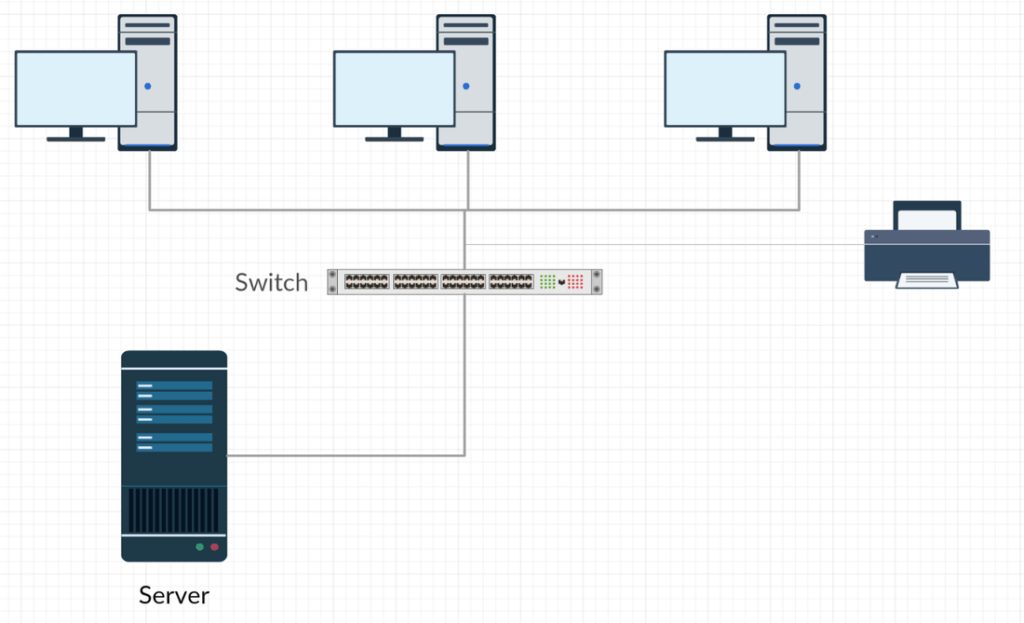
Its not a great diagram but it serves a purpose. Can you see that all the devices are first connected to a switch. The server then has one connection to a switch and can still communicate with all devices on the network. Any new devices simply have to be connected to a switch.
So, a client server network is one which has:
- Some kind of central point that devices are connected to – a switch
- One or more servers which are in control or have authority over the network
- Some devices that connect to the central switch (clients)
A server is simply a machine which has a dedicated purpose on a network such as:
- Authenticating log in attempts
- Storing users files (file server)
- Sending, receiving and storing email (mail server)
- Storing and processing web pages (web server)
The advantages of networking in this way are:
- You can manage the users and connections to your network
- Security – you can set “policies” centrally that apply to anyone that logs in to a machine
- Backup – you only need to copy data from one place – the servers.
- You can centrally manage software and configuration – you don’t need to go to each machine, just set it centrally and roll it out to devices.
- More secure and reliable than a P2P network
The disadvantages of the Client – Server model are:
- They usually require some kind of administrator to set up and maintain the servers, switches etc.
- All internet traffic is usually coming through a single connection, so you may need to pay for higher bandwidth than in a P2P model.
- You will need to buy server and switch equipment which is expensive.
Peer to Peer Networks
Peer to Peer (or P2P) networks work on the idea that every device is equal. They are unique in that no one single computer has control of the network, resources are shared between all devices on the network and devices can join and leave the network at any time.
Peer to Peer technology is usually used for file sharing and it grew in popularity significantly for this kind of activity (mainly people downloading music and films from Pirate Bay (which is a lesson in how the internet works in itself – the government blocked it and so now there are literally hundreds of mirrors. Yep, that stopped the pirates! You showed them…)) although more recently Peer to Peer technology is being used to share and roll out system updates, enable smoother media streaming and even to solving scientific and medical problems through distributed processing.
A Peer to Peer network is:
- One where each device has equal status on the network
- Each device offers up some resources to share on the network. This could be:
- Bandwidth
- Processing time/power
- Storage
- There is no central control – all devices must co-operate for the network to use.
The advantages of Peer to Peer networks are:
- Cheap to set up – you don’t need any servers or new infrastructure
- No need for an administrator
- Reduces the amount of bandwidth used/data that each device must send and receive
- Complex tasks can be split amongst many machines to distribute the work load
The disadvantages are:
- There is no easy way to ensure security
- There is no way to back up data easily on either individual devices or the network as a whole
- They are generally less reliable when compared to Client – Server networks as devices with important data on them can drop out of the network at any time. They also tend to use standard desktop PC hardware which can be less reliable than server hardware.
The Internet and the “Cloud”
The Internet
The internet is, to coin a phrase, pretty big. It’s also incredibly misunderstood and we need to kill the biggest myth/misunderstanding before we even start:
It is not Google, websites, instagram, Tiktok or any of your other favourite ways to post a picture of your dog and dinner. Many people believe that Google IS the internet and it really isn’t, it is a website and that is something completely different – that is part of the WWW or World Wide Web.

To understand the difference, you wouldn’t say that your car is “the road network.” That would be madness. The internet is just like the road network – it connects every town and city together and allows traffic to flow from one place to another. The internet does the same – connects networks together and allows data to travel from one device to another. Roads permit all kinds of different traffic – cars, buses, bikes, trams, motorcycles, horses etc. There is zero relationship between the network (road) and the traffic which flows down it.
The same is true of the internet – it allows all kinds of different traffic to flow from one device to another. The WWW is one type of traffic that uses the internet to get from web servers (where the website and all the information on it lives) to your device when you request it. The WWW is a collection of web pages that contain information, all linked together with hyperlinks. It was invented by Sir Tim Berners-Lee as a method of speeding up academic research in universities and the idea spread from there.
So why is Google not the internet? Because Google is a website – www.google.co.uk. See, it even has WWW in front of the address to tell you! It is a special type of website, though, as it exists to collect information about other websites and allow you to search it – it is a search engine. Something that enables you to find information on websites. The reason it is so popular is because there are trillions of websites and without a search engine you’d have a hard time finding the right one for you. Google happened to come up with the best way of finding information that you actually want (and trust me as an old person who was there, the WWW was like trying to find your way home in the dark with no street lights before Google)
Now that we have that out of the way – what actually is the internet?
Definition: the Internet is a global network of computer networks.
What that means in reality is that it is thousands of devices, and networks of devices, all connected together through some common, public and private transmission media.
Some people have tried to map out what the internet looks like, and it comes out as something like this:
The internet, therefore, is simply something that enables traffic to travel from one place (device, computer, server) to another.
What do you need to know for an exam?
- Internet = a global network of networks.
- WWW = some of the data that can travel on the internet, usually in the form of web pages.
- The internet operates a principle of net neutrality – all data packets are treated equally.
- Routers are used to join networks to other networks and forward packets between them
- Data travels in the form of packets (if you haven’t understood these then scroll up!)
DNS
As previously mentioned, the World Wide Web is a collection of web pages, containing information which are linked together via hyperlinks. Each website lives on a web server, which when contacted by your web browser, sends back a copy of the page.
Each web server will have an IP address on the network it is connected to. The problem here is that IP addresses aren’t exactly memorable, they don’t roll off the tongue. As a solution the idea of domain names was invented. A domain name is a user friendly name for a web server and when we type that into a web browser, it gets looked up by a system called DNS (Domain Name System) to discover the “true” IP address of the server, thus hiding the complexity (abstraction alert, see unit 2.1) from us as users and making the web easier to use.
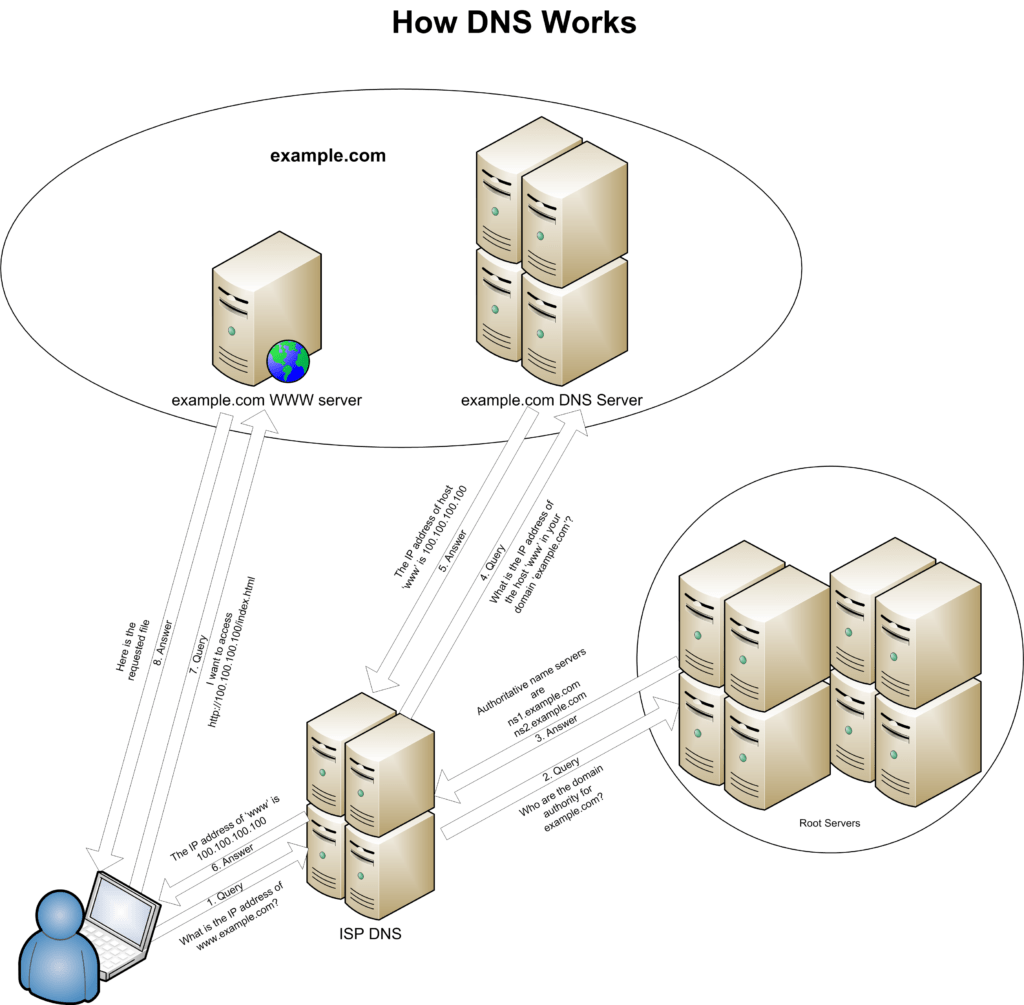
Lets look at how the Domain Name System works.
When you go to a website, you will type in to a browser the address of the site, for example:
www.interesting-but-weird-shaped-vegetables.com
This address is formally known as a URL, which stands for Uniform Resource Locator. This is a posh way of saying “an easy way to make and remember website addresses.”
Websites usually belong to some form of domain. A domain can indicate where a site is located or what type of site it is. Some examples are:
- .co.uk (a UK website)
- .org (an organisation)
- .gov (government websites)
- .sch.uk (schools)
- .ac.uk (universities)
The problem here is that a web server has no understanding of these addresses. URL’s are designed so we can easily understand and remember website addresses. As you may already have guessed, a web server simply has an IP address and this is how it can be found on the internet.
DNS stands for Domain Name Services (or server) and it is a server on a network which has one job – to translate a URL into an IP address.
There are trillions of web pages and many millions of website addresses and as such it would be impractical to keep them all in one place. Consequently, DNS servers are arranged in a hierarchical system and therefore your local DNS (maybe the one your ISP provides) will not know the IP address for every website in the world.
This is sensible – DNS servers are getting lots of traffic all the time (think about it – every time someone visits a site) and the load is distributed amongst many, many different servers. If for some reason the DNS you are connected to does not know the IP address you are looking for, it can pass it up the chain to another server to see if that has it instead.
To summarise the DNS process that you need to know for your exam:
- You type a URL in to your web browser
- This is sent to a DNS server
- The server looks up the URL in its database and IF a match is found, it returns this to your device
- If it is not found it passes the request to a higher DNS server.
- If it is then found the IP is passed back and a local copy cached in the DNS server you first used.
- If it is not found then an appropriate message is sent back to your device.
The cloud

The term “cloud” came about simply because no one knows what the internet looks like, which presents something of a problem when describing or drawing diagrams of it. The solution was to define the giant spaghetti monster that is the internet as a nice, fluffy cloud.
To be clear, Cloud = the internet. They are synonyms (posh way of saying those words have the same meaning)
Due to the fact that internet connection speeds have become so fast in recent years, we can now do more with the internet than ever before. Storage is now so cheap and processing power so ubiquitous that it is now possible to simply store your data somewhere else, on someone else’s computer that is connected to the internet somewhere. You’ve definitely used this kind of service, it’s called iCloud or Google Drive. This is just one form of cloud based service which have now become the norm for most of us.
There are three forms of cloud based service that you need to be aware of:
- Cloud Computing
- Cloud Storage
- Cloud Software
Cloud Computing
Despite modern computers being really quite powerful, with desktop machines commonly having 8-12 cores of CPU, 16GB ram and plenty of secondary storage, they are simply not powerful enough for some of the more demanding computing applications.
When we talk about computing power this refers to the number of CPU cores available to complete a task, the clock speed of those cores, the amount of RAM available for the temporary storage of data and the amount of secondary storage – in that order.
There are many uses of computers that require huge amounts of resources and computing power such as:
- Weather forecasting
- Climate modelling
- Analysing big data such as that generated by social media companies
- Scientific analysis and modelling – physics and chemistry simulations
- Engineering – stress and force analysis, aerodynamics
- Medical sciences – researching diseases and cures
- AI training and deployment
It is perfectly possible to build or create a computer capable of performing these tasks, and many institutions do just that. These computers can range from extraordinarily powerful desktop machines called “workstations” which are popular in design and engineering, all the way to clusters of computers or servers which have all been connected together to work as one large machine on a dedicated task split amongst them.
There are some disadvantages to this approach:
- It is extremely expensive – either to buy the equipment in the first place or, in the case of clusters of computers, to set up and administer.
- Scalability – problems and data sets have a habit of growing in size and complexity. To keep up with this you need to upgrade your system or add more computers to your cluster – this comes with an obvious cost implication
- Future proofing – computing hardware moves on at an alarming rate and what is state of the art today will be nothing special three years from now. There will be a need to upgrade entire computers at great expense.
Cloud computing offers a solution to all of these problems by effectively making them all someone else’s issue to worry about.
For our exam we can define cloud computing as performing computational tasks on hardware owned by a third party, through the internet.
Companies such as Microsoft, Amazon and Google own huge data centres which are packed with row upon row of powerful servers all attached to the internet. When you decide you need to use their computing power, they simply allocate some of this computing power to you and you can use it just as you would a normal computer sat right under your desk, there is no difference other than it isn’t physically in the same room nor do you actually own it.
This carries some amazing benefits, not least that you can use cloud computers for as little as a few minutes or hours, all the way up to months and years. At no point do you need to worry about paying for upgrades, backing up data or paying their absolutely monumental electricity bill.
To summarise cloud computing:
- It is using a computer, connected to the internet, which belongs to a company or organisation, to complete a complex or demanding task
- Cloud computing companies will charge you to use their computers based on how much power you need and how long you use them for
The benefits of cloud computing are:
- Cost – you do not have to buy, maintain or administer the hardware used
- Scalability – if your demands change, you can simply ask for more CPU cores, more RAM, more storage. Amazon boast that you cannot run out of storage on their systems.
- Obsolescence – It is the job of the cloud computing company to ensure their servers, CPU’s, RAM etc are all up to date and they pay for this.
There are, of course, some negatives:
- It can be expensive as you scale up and demand more processing power (although still likely less expensive than maintaining your own equipment).
- You are reliant on your internet connection being reliable to access the remote system and send data to and from it.
Cloud Storage
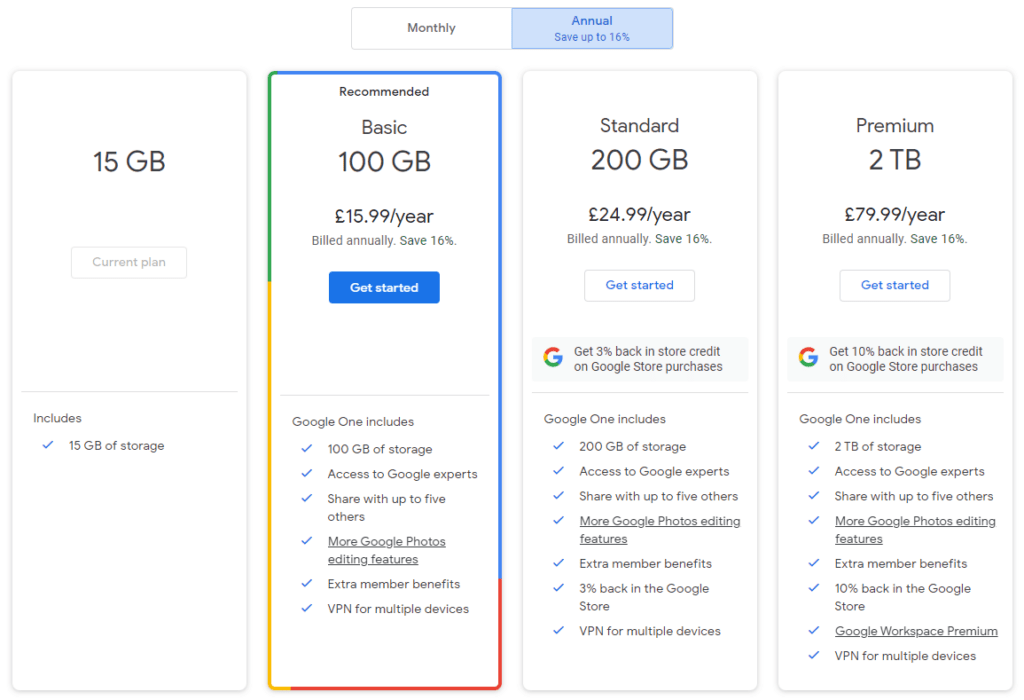
Computer users own and generate more data than ever before. Whether this is video files, pictures, documents or data from a project, we are storing terabytes of information without so much as a second thought. If you own a relatively recent games console, you’ll know that modern games are huge, to the point where you can fit approximately three AAA games on a PS5.
Storage is stupendously cheap these days. Large hard drives that can store more than 20TB each are widely available, with prices averaging around £25 per TB or 2.5p per gigabyte. 20 years ago it would’ve been considered reasonable to charge £1 per GB and prices are only ever going to fall further.
This is fine for local storage, saving things on your own computer, but it presents a huge problem when you need to either move that data around or access it from somewhere else. Many of us face this issue on a day to day basis, if you write a document at home you need access to it when you arrive at school for example. You could resort to things like memory sticks, but then you end up with multiple copies of your work – which one is the most recent copy? What happens if you lose your memory stick?
Cloud storage is an incredibly convenient solution to this problem and many more. To define, cloud storage is storage space provided by a third party, accessed through the internet.
If this sounds similar to cloud computing, that’s because it is. Many well known companies offer a cloud storage product such as:
- Apple – iCloud Drive
- Google – Google Drive
- Microsoft – OneDrive
- DropBox
- Amazon – AWS

Cloud storage is literally nothing more than users renting hard drive space from a company, which can be accessed through a web browser or phone/tablet app. Usually they integrate with operating systems such as Windows and MacOS so you can simply save files to cloud storage in the same way you would to the internal storage of a computer.
As you may expect, cloud storage offers multiple advantages:
- Accessibility – you can view, edit, upload your files from anywhere and any device which has internet connectivity
- Scalability – if your requirements grow, companies will gladly sell you more storage. Amazon maintain you cannot run out of storage on their systems.
- Backup – cloud storage is usually very reliable and is probably (but not always!) backed up by the provider
- Can be used as backup – cloud storage is a cheap, effective way of making a backup of your files, which are stored off site (away from your computer) and can be used in disaster recovery
- Cost – cloud storage can be very cheap and could be cheaper than buying hard drives or SSD’s and replacing them when they wear out
- Cost – you do not need to worry about replacing broken or damaged drives as you don’t own them
On the negative side:
- In the long term it may be more cost effective to buy your own drives
- You do not have any control over where your data is stored
- Security – passwords may be compromised, which gives access to all of your data. Anything connected to a network is vulnerable to attack
- Reliant on an internet connection – you may not be able to work if your internet connection fails.
Cloud Software
Cloud software is becoming more and more popular. It is seen by some users and companies as the future of how software will be provided as web browsers become more capable and internet connections faster and more reliable.
Cloud software is, as you have probably guessed, software which is available to use in a web browser or is provided through an internet connection. The data for the software package is not stored on your computer and bits are downloaded only as and when necessary.
Cloud software is controversial because it removes the ownership of software from users. If you stop paying your subscription fee, you lose access to software. If an office package costs £100 to buy up front, but is also available for £10 a month, you can clearly see that after 10 months, you are paying more for the privilege of using an online version.
Furthermore, there is no guarantee that providers will continue to support cloud software that you have invested in. At any point, they can (and do) simply turn off their server and that is the end of you being able to use their software. It is for these reasons that some users dislike the cloud model and will stick to buying physical copies of software.
Examples of cloud software include:
- Microsoft 365 (office online)
- Adobe creative suite (online versions)
- Apple iWork – through icloud.com
- Gamepass and other gaming services where games are streamed to your device, not installed on them.
There are advantages to cloud software:
- Software can be used on devices that do not have a great deal of processing power
- Access can be very cheap to cloud applications
- Can be accessed anywhere where you have an internet connection
However, on the downside:
- Applications are usually much less powerful than their desktop equivalents
- Some features may be missing
- Speed and responsiveness can be affected by the browser used and the quality of internet connection
- Subscription models mean that access to software can be lost
Hosting
Hosting refers to the place where a website and its associated files are stored.
At the most basic a website is simply a collection of HTML files and probably some associated images. These are all stored on a web server. If you remember, a server is simply a computer connected to a network with a dedicated purpose – in this case its purpose is to wait for requests for the website and then to send the appropriate files back.
The WWW has grown in complexity significantly since the days of basic, static HTML pages. Websites now are nearly all dynamic, connected to a database and each page is generated on the fly as they are requested by users. This dynamic content requires processing power from the server and if the website is popular then the demand on the CPU is significant.
Furthermore, websites now come under constant attack from bots which are searching for security vulnerabilities and weaknesses so that data can be stolen or the website compromised in some case. Whilst it is possible to set up a web server at home, it is not recommended unless you know what you are doing and can properly secure it to prevent your entire home network from being compromised.
A host is a company which sets up dedicated, powerful web servers and configures them for popular websites that users may wish to create. They deal with all of the security and administration of a web server and ensure that your site is available 24/7. All files are stored on their servers and they should also create backups of your website for you. In return, as you probably guessed, users pay a monthly or yearly fee for these services.